RAM is the new disk, at least in the In-Memory computing world.
No, I am not talking about Flash here, but Random Access Memory – RAM as in SDRAM. I’m by far not the first one to say it. Jim Gray wrote this in 2006: “Tape is dead, disk is tape, flash is disk, RAM locality is king” (presentation)
Also, I’m not going to talk about how RAM is faster than disk (everybody knows that), but in fact how RAM is the slow component of an in-memory processing engine.
I will use Oracle’s In-Memory column store and the hardware performance counters in modern CPUs for drilling down into the low-level hardware performance metrics about CPU efficiency and memory access.
But let’s first get started by looking a few years into past into the old-school disk IO and index based SQL performance bottlenecks :)
Have you ever optimized a SQL statement by adding all the columns it needs into a single index and then letting the database do a fast full scan on the “skinny” index as opposed to a full table scan on the “fat” table? The entire purpose of this optimization was to reduce disk IO and SAN interconnect traffic for your critical query (where the amount of data read would have made index range scans inefficient).
This special-purpose approach would have benefitted your full scan in two ways:
- In data warehouses, a fact table may contain hundreds of columns, so an index with “only” 10 columns would be much smaller. Full “table” scanning the entire skinny index would still generate much less IO traffic than the table scan, so it became a viable alternative to wide index range scans and some full table scans (and bitmap indexes with star transformations indeed benefitted from the “skinniness” of these indexes too).
- As the 10-column index segment is potentially 50x smaller than the 500-column fact table, it might even fit entirely into buffer cache, should you decide so.
This is all thanks to physically changing the on-disk data structure, to store a copy of only the data I need in one place (column pre-projection?) and store these elements close to each other (locality).
Note that I am not advocating the use of this as a tuning technique here, but just explaining what was sometimes used to make a handful critical queries fast at the expense of the disk space, DML, redo and buffer cache usage overhead of having another index – and why it worked.
Now, why would I worry about this at all in a properly warmed up inmemory database, where the disk IO is not at the critical path of data retrieval at all? Well, now that we have removed the disk IO bottleneck, we inevitably hit the next slowest component as a bottleneck and this is … RAM.
Sequentially scanning RAM is slow. Randomly accessing RAM lines is even slower! Of course this slowness is all relative to the modern CPUs that are capable of processing billions of instructions per core every second.
Back to Oracle’s In-Memory column store example: Despite all the marketing talk about loop vectorization with CPU SIMD processing extensions, the most fundamental change required for “extreme performance” is simply about reducing the data traffic between RAM and CPUs.
This is why I said “SIMD would be useless if you waited on main memory all the time” at the Oracle Database In-Memory in Action presentation at Oracle OpenWorld (Oct 2014):
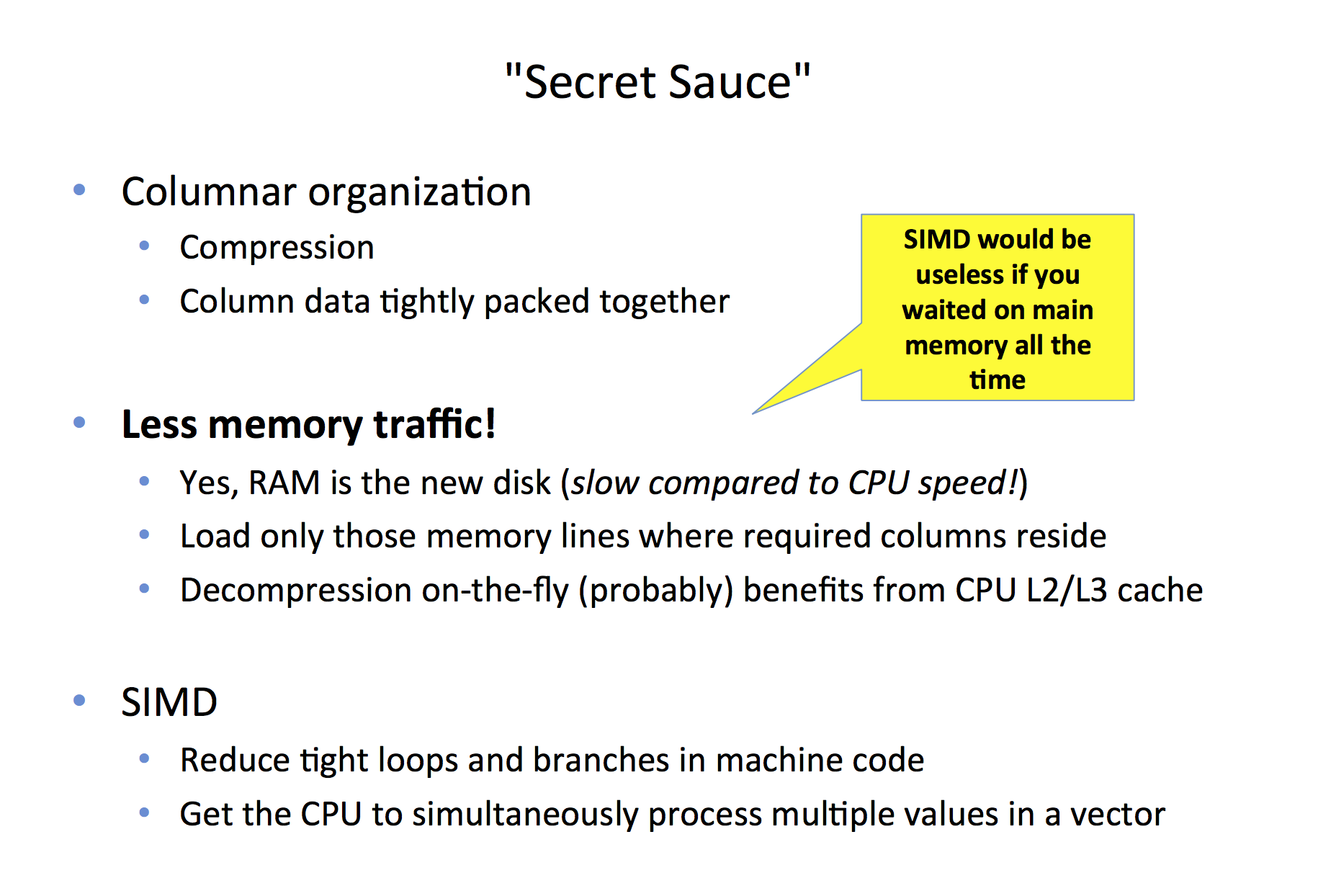
The “secret sauce” of Oracle’s in-memory scanning engine is the columnar storage of data, the ability to (de)compress it cheaply and accessing only the filtered columns’ memory first, before even touching any of the other projected columns required by the query. This greatly reduces the slow RAM traffic, just like building that skinny index reduced disk I/O traffic back in the on-disk database days. The SIMD instruction set extensions are just icing on the columnar cake.
So far this is just my opinion, but in the next part I will show you some numbers too!
